当今,互联网的应用几乎席卷了社会的每个角落。人们利用互联网获取信息和知识、发表个人意见或进行社交和娱乐等。互联网上的这些活动大多以语言为媒介来完成,平均每小时就有海量的语言数据产生,故成为可观察语言使用变化以及用户语言行为的大数据库。
语言是社会心理和社会现象的反映,即新事物会很快催生新的词语、新的语义或其它语言层面上的变化。这些变化往往意味着社会生活的某种变化。2020年1月“不明原因肺炎”突袭我国武汉并快速波及其它省市。这场突如其来的疫情不仅造成了医疗资源和防疫物资的短缺,也造成了准确描述和表达这种未知疾病的语言资源的短缺。在疫情的早期,医护人员、媒体等采用了“不明原因肺炎”“新型肺炎”等词语来指称该疾病,民间则出现了更多不同的、甚至带有歧视性的名称。

图1 新冠疫情不同命名搜索数据对新冠疫情新增病例预测的可解释力(>0.9)
西安交大外国语学院与香港理工大学人文学院科研人员采用“百度指数”平台上2019年12月21日至2020年6月28日“新冠疫情”相关的大数据,通过计算不同新冠词语的使用频数观察不同新冠命名词语之间的竞争和变化趋势。同时,该研究讨论了影响不同“新冠”词语使用的社会因素以及影响百度网络“新冠”搜索频次的社会因素、尤其与疾病本身变化的相关性。研究结果表明:新冠疫情在百度指数上的搜索频次和新冠疫情病例之间呈现强相关关系;相对于简单线性回归和逻辑回归,二次项回归函数可以更准确地描述并模拟新冠疫情搜索频次和新冠疫情病例之间的数学映射关系。图1展示了新冠疫情命名的搜索频数对新冠疫情新增病例的预测解释力(R2)超过0.9的组对(pairs),其中二次项函数(binomial)对新冠疫情搜索频次和新冠疫情病例的解释力最强。
网络新冠疫情新词搜索的历时变化
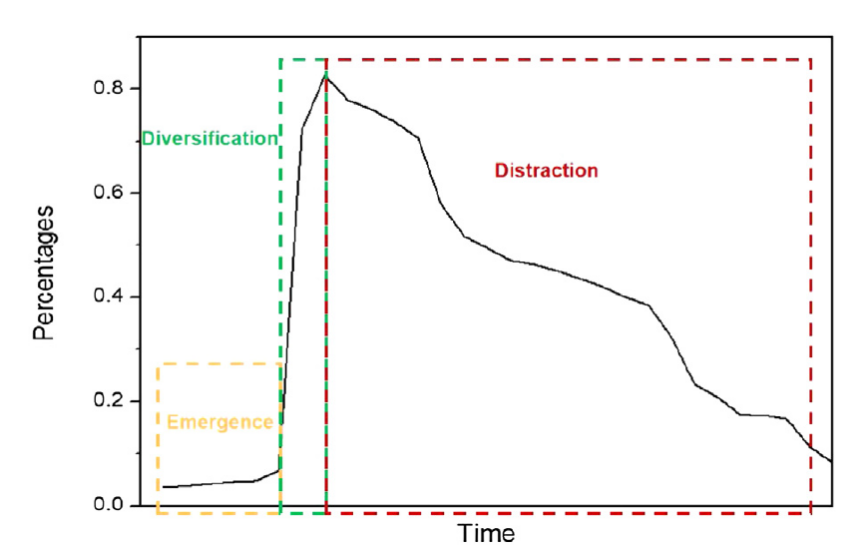
此外,该研究还发现:不同于传统描述新词发展的S曲线(产生—上升/扩散—消亡/分散),新冠疫情的新词发展呈现变形的S曲线(skewed S curve),即从产生(Emergence)到扩散(Diversification)之间呈现更为迅速的指数上升态势,而在扩散到高点之后,公众注意力的消亡或分散(Distraction)过程则呈现缓慢下降的趋势(见图2)。这种变形的S曲线反映了危害人类公共健康类事件所具有的扩散快速而消散缓慢的特点。
该研究不仅发现突发公共卫生事件相关词语的扩散轨迹不同于日常新词语的变化轨迹,同时也发现新冠疫情网络搜索频数与其对应的社会现象或事件,即新冠疫情病例发生数量之间呈现的强相关关系。这种强相关关系为将来通过语言大数据预测潜在疫情或其它社会事件提供了新的思路与方法。研究突破了传统语言学的研究范式,体现了语言研究在认识与了解社会现象及其变化方面的巨大潜力。
该项研究成果发表在应用语言学国际知名学术期刊《语言》(Lingua)上,并获得Editors’ Choice Article的荣誉。本年度该项荣誉仅有8篇文章入选,约占年度发表论文的10%。
该研究工作由西安交大外国语学院教授杨瑞英、香港理工大学人文学院教授黄居仁与两校联合培养的博士生雷司宇共同完成的。雷司宇为论文第一作者,杨瑞英、黄居仁为共同通讯作者,西安交通大学为第一作者单位。
论文链接:https://www.journals.elsevier.com/lingua/editors-choice/editors-choice-articles-lingua








