近日,北京大学药学院联合西安交通大学人工智能与机器人研究所(以下简称“人机所”)、华盛顿大学、香港中文大学及石河子大学等单位,在小分子天然产物智能表征与药物发现研究方面取得新进展。研究团队提出了面向小分子天然产物的基础模型NaFM(Foundation Model for Natural Products),相关成果以《小分子天然产物的基础模型预训练》(Pretraining a foundation model for small-molecule natural products)为题,发表于国际高水平期刊《自然机器智能》(Nature Machine Intelligence)。

在该研究中,西安交大人机所郑南宁院士团队深度参与了模型架构设计与人工智能方法开发工作。北京大学刘振明教授、西安交大人机所郑南宁教授以及博士生王裕淞为本文共同通讯作者,北京大学硕士生丁宇恒为第一作者。
天然产物是由微生物、动物或植物产生的代谢产物,具有结构多样性高、生物活性丰富等特点,是抗肿瘤、抗感染等药物发现的重要来源。然而,其发现过程长期面临周期长、成本高、标注数据有限等挑战。现有深度学习方法多依赖单一任务的监督学习,模型泛化能力有限;而针对合成分子的通用表征方法,也难以刻画天然产物在来源、骨架结构、合成途径与生物活性之间的复杂关联。进一步而言,天然产物在化学空间中呈现出以核心母核(scaffold)为中心的层级化分布特征,并与通用化合物空间存在显著分布偏移(distribution shift),导致现有模型难以直接迁移应用。因此,构建面向天然产物结构与生物学约束的专用预训练范式尤为迫切。为此,研究团队以分子母核为核心构建表征框架,系统刻画并对齐天然产物在生物来源、生物合成基因簇、合成途径及生物活性等多维属性之间的内在关联,提出了母核感知的预训练策略。
NaFM将掩码图学习与对比学习相结合:一方面,在天然产物分子骨架区域进行子图掩码,要求模型同时重建原子属性、化学键属性和拓扑连接信息;另一方面,以骨架相似性作为软权重,引导模型区分不同分子之间的强弱负样本关系,从而更有效地学习天然产物的进化规律与结构特征。在预训练阶段,研究团队基于COCONUT 数据库中约60万条未标注天然产物结构数据,构建了面向天然产物的分子表示学习框架。实验结果表明,相较于传统分子指纹和多种预训练图神经网络方法,NaFM在天然产物分类、来源识别、基因组挖掘、活性预测和虚拟筛选等任务中表现出更强的迁移能力和鲁棒性。
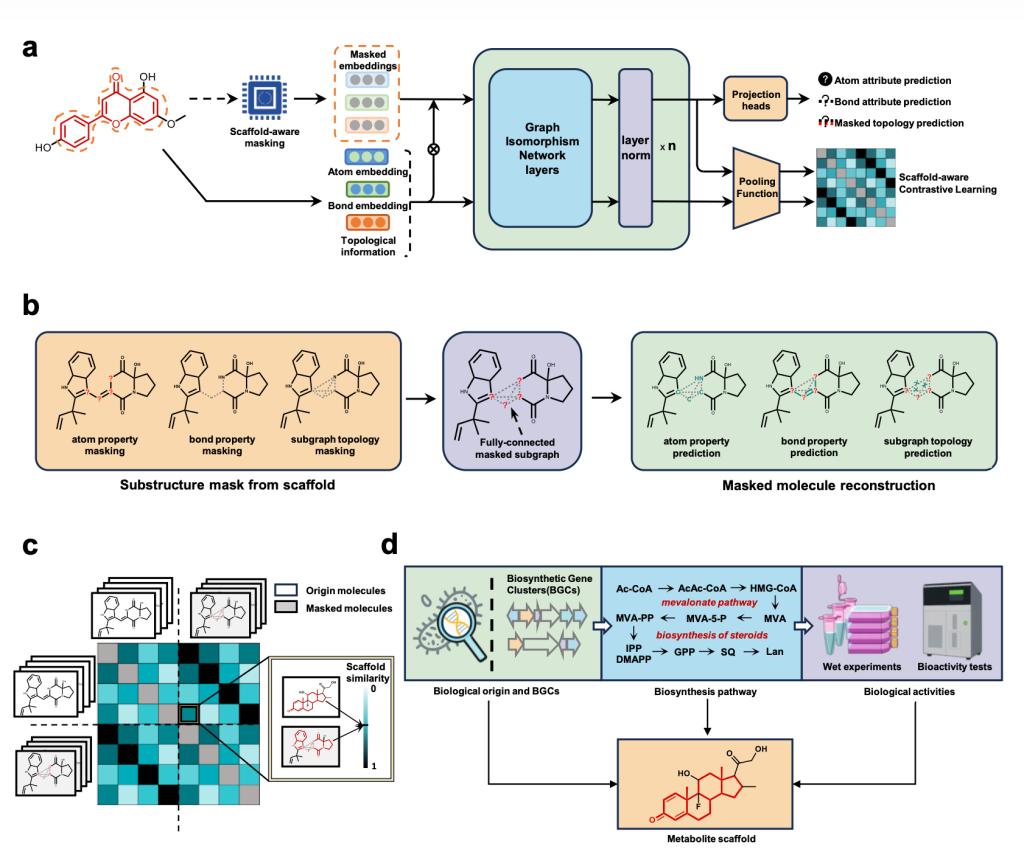
NaFM的母核感知预训练框架。该框架结合母核子图重建与母核感知对比学习:在天然产物核心骨架区域遮蔽原子、化学键和拓扑连接信息,并基于骨架相似性加权对比学习,从而捕获天然产物生物来源、生物合成基因簇、合成途径与生物活性之间的内在关联。
论文链接:https://www.nature.com/articles/s42256-026-01226-8








